at_each_aligned¶
Utilization of SIMD instructions is one of the keys to getting the most performance out of your CPU. Many SIMD operations only work on pieces of data with specific alignment; depending on the instruction, misaligned operands can either fault or simply perform very slowly. When writing a function which wishes to utilize SIMD, there are two options for dealing with misaligned memory. The first option is to simply reject problematic arguments with an error of some sort. The second option is to write code for handling the potentially-misaligned front and back of the input range.
The biggest problem with handling the misaligned code is the code to handle it is annoying and error-prone to write.
Luckily, C++ provides nice facilities for generic programming so we can Write Once, Run AnywhereTM.
The std::for_each function (that thing you used before
Boost.Foreach and
range-based for were introduced) provides a good pattern for
creating a function to help.
The function will be called at_each_aligned:
template <typename... TFArgs, typename... FApply>
void at_each_aligned(char* first, char* last, FApply&&... transform);
Like our old friend std::for_each, it operates on the half-open range \([\mathtt{first}, \mathtt{last})\) and
accepts a function to operate on the contents.
The key difference is ... FApply, which accepts multiple functions.
These functions are invoked based on the alignment of the element we are processing.
In other words, if at_each_aligned gets input aligned to 8 bytes, the function will call the provided transform
that accepts a std::uint64_t.
Slightly more visually, if a the function is provided with first = 0x21, last = 0x31, and transform
functions which operate on 1-, 2-, 4-, and 8-byte alignments, the access pattern should look like this:
Addr: 0x20 0x21 0x22 0x23 0x24 0x25 0x26 0x27 0x28 0x29 0x2a 0x2b 0x2c 0x2d 0x2e 0x2f 0x30
Buffer: [ first ====================================================================================== ] last
Access: [ 1 ][ 2 ------ ][ 4 ------------------ ][ 8 ------------------------------------------------ ]
Similarly, if the input is misaligned at the end:
Addr: 0x20 0x21 0x22 0x23 0x24 0x25 0x26 0x27 0x28 0x29 0x2a 0x2b 0x2c 0x2d 0x2e 0x2f 0x30
Buffer: [ first ====================================================================================== ] last
Access: [ 8 ------------------------------------------------ ][ 4 ------------------ ][ 2 ------ ][ 1 ]
Implementation¶
The general operation of this function is quite simple:
template <typename... FApply>
void at_each_aligned(char* first, char* last, FApply... transforms)
{
while (first != last)
{
// Get the maximum distance we can stride that properly aligns in memory and does not
// jump off the end of the buffer. Also get the associated transformation function the
// caller wants to apply.
auto [stride_size, transform] = get_highest_stride(first, last, transforms);
transform(first);
first += stride_size;
}
}
While the above code is valid C++, there is no way to write get_highest_stride.
Since the selected FApply function will have a different type based on the value of first and last, there is
no way to specify the return type.
Returning an index would work, but the mechanism used to select from transforms would be subject to the same
problem of having an inexpressible type.
std::function would allow get_highest_stride to be written, but the resulting indirection would kill any
performance goals.
The fallback to these un-writable things is to use recursion:
namespace detail
{
template <typename... TFArgs>
struct at_each_aligned_impl;
template <typename TFArg, typename... TFArgRest>
struct at_each_aligned_impl<TFArg, TFArgRest...>
{
static constexpr std::size_t byte_align = sizeof(TFArg);
template <typename TChar, typename FApply, typename... FApplyRest>
__attribute__((always_inline))
static TChar* step(TChar* first, TChar* last, const FApply& apply, const FApplyRest&... apply_rest)
{
if (reinterpret_cast<std::uintptr_t>(first) % byte_align == 0
&& first + byte_align <= last
)
{
apply(reinterpret_cast<TFArg*>(first));
return first + byte_align;
}
else
{
return at_each_aligned_impl<TFArgRest...>::step(first, last, apply_rest...);
}
}
};
template <typename T>
struct at_each_aligned_impl<T>
{
static_assert(sizeof(T) == 1, "You must provide a single byte type to at_each_aligned");
template <typename TChar, typename FApply>
__attribute__((always_inline))
static TChar* step(TChar* first, TChar*, const FApply& apply)
{
apply(reinterpret_cast<T*>(first));
return first + 1;
}
};
template <typename... TFArgs, typename TChar, typename... FApply>
void at_each_aligned(TChar* first, TChar* last, FApply&&... transform)
{
for ( ; first < last; /* inline */)
{
first = at_each_aligned_impl<TFArgs...>::step(first, last, transform...);
}
}
}
One thing that might stand out as odd is the use of __attribute__((always_inline)).
While the compiler is usually pretty smart, it is very common for it to struggle inlining code with deep recursion.
It seem that neither GCC 6.3.1 nor LLVM 4.0.0 will inline all the way back to the user-supplied functions without being
forced to.
Using this makes all code end up in the top-level at_each_aligned function, where the compiler can more easily
figure out what is going on.
The use of TChar might seem a bit odd, since at_each_aligned is designed for and constrained to byte
manipulation.
This is used to allow code to be written based on char* and const char* inputs.
Ultimately, the implementation in the detail namespace are wrapped in these slightly more user-friendly functions:
template <typename... TFArgs, typename... FApply>
void at_each_aligned(char* first, char* last, FApply&&... transform)
{
detail::at_each_aligned<TFArgs...>(first, last, std::forward<FApply>(transform)...);
}
template <typename... TFArgs, typename... FApply>
void at_each_aligned(const char* first, const char* last, FApply&&... transform)
{
detail::at_each_aligned<const TFArgs...>(first, last, std::forward<FApply>(transform)...);
}
Performance¶
So how do functions written with at_each_aligned compare to their hand-written counterparts?
To test this, we need to pick a function.
In this case, we’ll use CRC32, as it is easy to understand, easy to write, and there are instructions for it in SSE 4.2.
With at_each_aligned, crc32 is written like this:
std::uint32_t crc32(const char* first, const char* last)
{
std::uint32_t code = ~0U;
at_each_aligned<std::uint64_t, std::uint32_t, std::uint16_t, std::uint8_t>
(
first, last,
[&] (const std::uint64_t* p64) { code = _mm_crc32_u64(code, *p64); },
[&] (const std::uint32_t* p32) { code = _mm_crc32_u32(code, *p32); },
[&] (const std::uint16_t* p16) { code = _mm_crc32_u16(code, *p16); },
[&] (const std::uint8_t* p8) { code = _mm_crc32_u8( code, *p8); }
);
return ~code;
}
The hand-written version of this approximately the same, but takes up a bit more space:
std::uint32_t crc32_hand(const char* first, const char* last)
{
std::uint32_t code = ~0U;
while (first + 1 <= last
&& (reinterpret_cast<std::uintptr_t>(first) % 2 != 0 || first + 2 > last)
)
{
code = _mm_crc32_u8(code, *reinterpret_cast<const std::uint8_t*>(first));
first += 1;
}
while (first + 2 <= last
&& (reinterpret_cast<std::uintptr_t>(first) % 4 != 0 || first + 4 > last)
)
{
code = _mm_crc32_u16(code, *reinterpret_cast<const std::uint16_t*>(first));
first += 2;
}
while (first + 4 <= last
&& (reinterpret_cast<std::uintptr_t>(first) % 8 != 0 || first + 8 > last)
)
{
code = _mm_crc32_u32(code, *reinterpret_cast<const std::uint32_t*>(first));
first += 4;
}
while (reinterpret_cast<std::uintptr_t>(first) % 8 == 0
&& first + 8 <= last
)
{
code = _mm_crc32_u64(code, *reinterpret_cast<const std::uint64_t*>(first));
first += 8;
}
while (first + 4 <= last)
{
code = _mm_crc32_u32(code, *reinterpret_cast<const std::uint32_t*>(first));
first += 4;
}
while (first + 2 <= last)
{
code = _mm_crc32_u16(code, *reinterpret_cast<const std::uint16_t*>(first));
first += 2;
}
while (first + 1 <= last)
{
code = _mm_crc32_u8(code, *reinterpret_cast<const std::uint8_t*>(first));
first += 1;
}
return ~code;
}
How do they stack up against each other? Running this on a Intel Core i7-6700K with input buffers of various size yields:
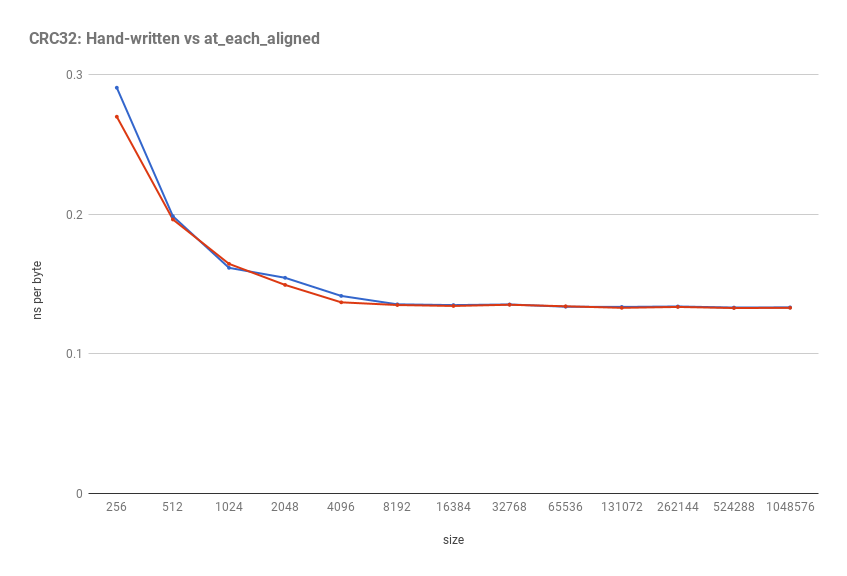
The answer appears to be “approximately the same.” In other words: use of lambda functions and templates does not hurt performance in C++ (as long as inlining happens properly).
More Info¶
Source Code¶
The source code for this post can be found as part of YarrPP in yarr/algo/at_each_aligned.hpp and yarr/algo/at_each_aligned.ipp.
Performance Blog Post¶
For more information and a more story-driven read, check out the two-part blog post on the Bidetly.
There are a few changes to the implementation described in the blog posts, the most obvious one is that you specify the
types in at_each_aligned instead of the “size in bytes.”
This is more convenient for most cases, but the char (*p)[512] syntax is a little bit awkward.